In my honest (and truly humble) opinion, VPCs don’t make much sense in a serverless architecture — it’s not that they don’t add value, it’s that the value the add isn’t worth the complexity you incur.
After all, you can’t log into a lambda function, there are no inward connections allowed. And it isn’t a persistent environment, some functions may timeout after just 2-3 seconds. Sure, network level security is still worthy pursuit, but for serverless, tightly managing IAM roles and looking after your software supply chain for vulnerabilities would be better value for your money.
But if you’ve got a fleet of EC2s already deployed in a VPC, and your Lambda function needs access them. Then you have no choice but to deploy that function in a VPC as well. Or, if your org requires full network logging of all your workloads, then you’ll also need VPC (and their flow logs) to comply with such requests.
Don’t get me wrong, there is value in having your functions in a VPC, just probably not as much as you think.
Put that aside though, let’s dive into the wonderful world of Lambda functions and VPCs
Working Example
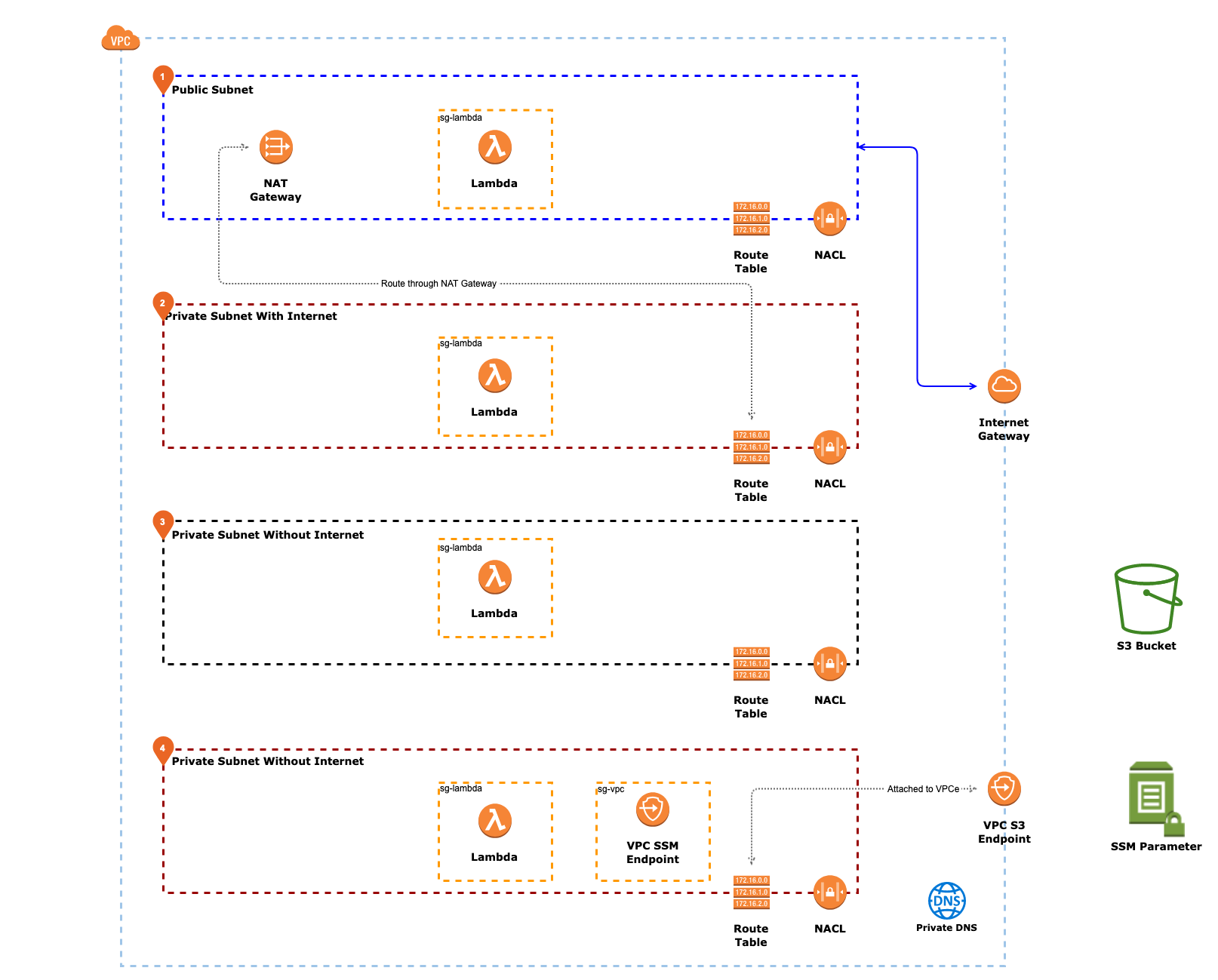
First, imagine we deploy a simple VPC with 4 subnets.
- A Public Subnet with a Nat Gateway inside it.
- A Private Subnet which routes all traffic through that NAT Gateway
- A Private Subnet without internet (only local routing)
- A Private Subnet without internet but with a SSM VPCe inside it
Let’s label these subnets (1), (2) ,(3) and (4) for simplicity.
Now we write some Lambda functions, and deploy each of them to each subnet. The functions have an attached security group that allows all outgoing connections, and similarly each subnet has very liberal NACLs that allow incoming and outgoing connections.
Then we create a gateway S3 VPC-endpoint (VPCe), and route subnet (4) to it.
Finally, we enable private DNS on the entire VPC. And then outside the subnet we create a bucket and an System Manager Parameter Store Parameter (AWS really need better terms for these things).
The final network looks like this:
S3 Bucket Example
Now here’s the question.
Assuming the Lambda functions have proper IAM access — which subnets functions are going to be able to connect to the S3 Bucket?
The answer is (2) and (4), and here’s why:
(1) has no access to the S3 bucket, because Lambda functions don’t have a working network interface when deployed on public subnets. The functions will run, but simply time-out whenever they need to make network calls (like to the S3 API). This odd behavior is something to remember, as an EC2 in the same scenario would work perfectly, and the error from the function is very confusing.
(2) has access to the S3 API via the internet. It connects out through the NAT Gateway, and out through the internet to the S3 API.
(3) is completely locked down and hence the function will timeout.
(4) has access to the VPC S3 Endpoint, meaning its traffic is routed internally to the gateway VPCe, and onto the S3 API directly.
Here’s a lesson, everything in/out of the Lambda function is via a network interface, and since Lambdas in a Public Subnet don’t work … you need at least a NAT Gateway or VPC-endpoint for Lambda functions to operate in a VPC.
NAT Gateways are expensive (and not serverless), while VPC-endpoints are service specific, so you need one for every service you plan to access from the functions. Hence, VPCs with lambda functions introduce a higher level of complexity over simple functions on the internet.
Limiting S3 access to just the VPC
If we then modified the resource policy on the bucket to allow access from only the specific VPC-endpoint in question, we could disable access to subnet (2), leaving only 1 subnet full access to the bucket:
This is because subnet (2) accesses the bucket via the internet, while subnet (4) routes traffic via the VPC-endpoint. Both will reach the bucket, but the bucket policy will deny access to subnet (2) because it did not originate from the VPC-endpoint.
Remember this is tied to the VPCe (the endpoint!) and not the VPC, traffic from the VPC will still be denied if it was routed over the internet.
Note that the policy above only covers the permissions to the S3 ‘objects’ and not the bucket itself. You’ll still be able to list bucket permissions etc from outside the VPCe, I did this to avoid a situation where I couldn’t control the bucket except via the VPCe (and be forced to nuke the bucket policy via the console of a root user login).
Now let’s look at another example.
SSM Parameter Example
Assuming the Lambda functions have proper IAM access — which subnets functions are going to be able to connect to the SSM Parameter?
The answer is (2), (3) and (4).
(1) fails for the same reason as above — lambda functions in a public subnet have a broken network connection. Don’t bother!
(2) succeeds because internally it is routed to the VPC-endpoint, this is the difference between a gatewayVPC-endpoint like for S3 and Dynamo, and aninterface VPC-endpoint for SSM (and just about everything else). gateway endpoints are tied to subnets via routing tables, while interface endpoints are tied to the entire VPC via setting the private DNS. In theory, if you set the DNS settings of the lambda function to point to an external resolver this might route differently, but again that’s a high level of complexity.
(3) and (4) succeed for the same reason. Note, that since we didn’t mess around with the route tables, all traffic internal to the VPC was routed correctly.
Here, we can limit connectivity to a single subnet by using the security group of the endpoint. The security group of an SSM VPCe requires opening incoming connections on port 443, but we can limit it by specifying the private IP addresses of the subnets we wish to grant access to. Lambda functions on subnets not explicitly allowed by the security group, would time-out when trying to reach SSM.
Conclusion
I personally feel VPCs are un-necessary for Lambda functions. We’ve taken a concept built for datacenters, and extended them to cloud native lambda functions.
An EC2 instance is a long-running process, and has an operating system which can be compromised. A lambda function is an ephemeral process, running as a low-privileged user in a sandbox. Add to that, lambda functions do not allow inward connections anyway, hence network level control (while still effective) aren’t as useful as other things you want to spend your time on.
Traditional architectures require connectivity to database servers locked in isolated networks except to a select few application servers. We use VPCs to execute this paradigm.
But modern serverless architectures use DynamoDB instead, which is accessible via the internet regardless of what your VPC says (you only control access via IAM policies) — network level controls mean very little here. Plus all DynamoDB calls are encrypted anyway, and aggregated across the network, and fully redundant across AZs in a region.
Also, unless you deploy your function in subnets across all AZs in your region, you’ll actually degrade the natural resiliency of lambda (which does deploy across all AZs without any extra effort from you!!)
But if you absolutely must, for example because the function needs access to resource in the VPC — then just beware of two things. Lambda functions only work correctly in a private VPC, and perhaps you might want to re-think if you really want to do this!
From a security perspective, AWS seem to agree with me. I recently took the serverless lens on the Well Architected Framework, and this question poped-up. Even though I didn’t tick the network controls, the question didn’t surface any warnings.

TL;DR
My IAC (infra-as-code) scripts to create the VPC and deploy the lambda functions are here: https://github.com/keithrozario/VPC-Notes
Feel free to use them.