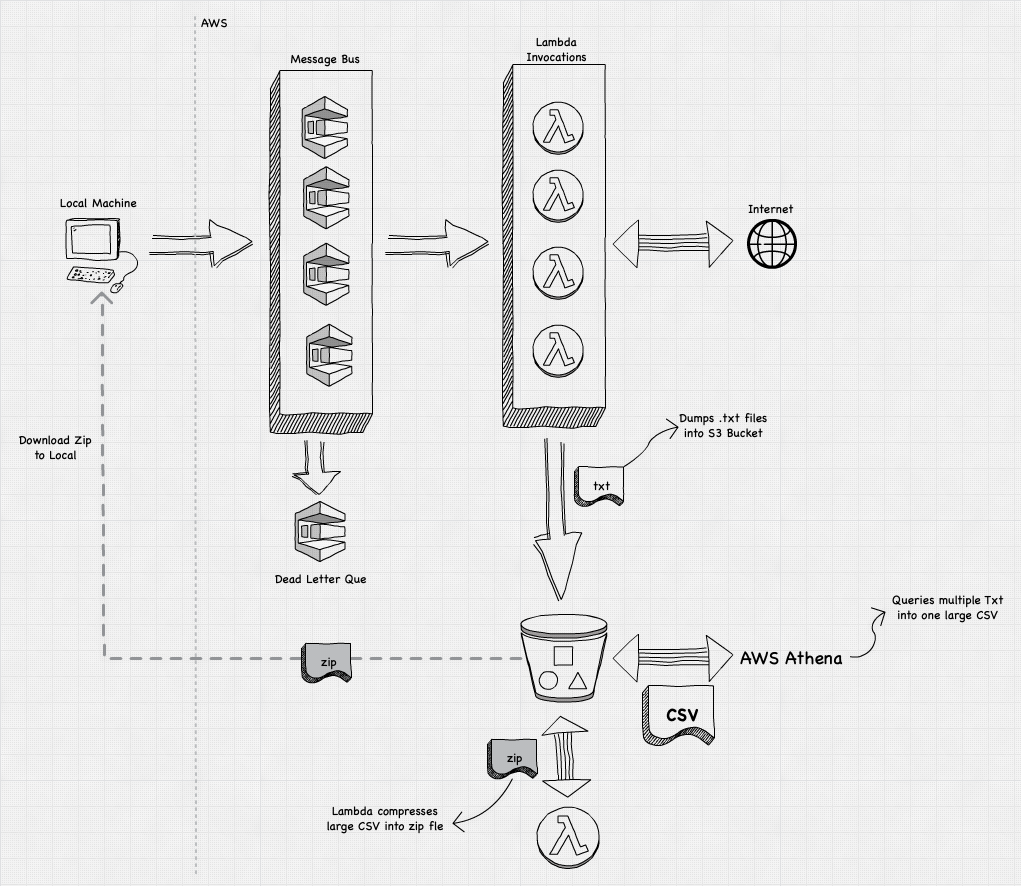
Potassium40 was a project I started to see how fast Lambda could really go. The project attempts to download the robots.txt files from 1 million websites as fast as it can. I chose robots file because — well it’s supposed to be downloaded by robots anyway, so this was both great fun, but also completely ethical as I wasn’t scraping people’s websites.
The goal is still to get everything down to 5 minutes, I’m still not there 🙁
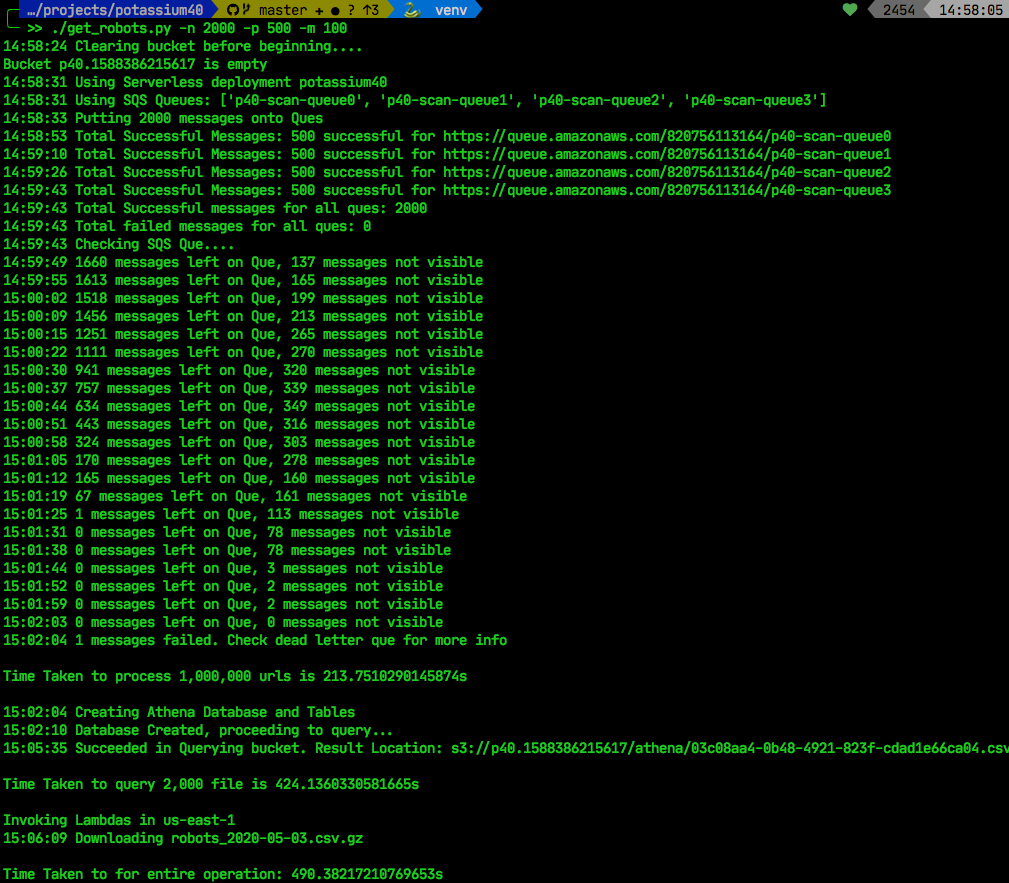
But by sharding my SQS ques I managed to shave off 100 seconds in total execution time, and now we’re down to just over 7 minutes.
Sharding SQS Ques
The initial architecture directly invoked 800 Lambdas in parallel (from a boto3 call on the local machine), and then checked cloudwatch logs to see when all the lambdas were complete.
That was bad — as cloudwatch logs are slow, and trying to query them was even slower. The cloudwatch API wasn’t built was this kinda thing — even when I tried metrics, or simple cloudwatch insights queries, the delay was even greater.
Later on, I replaced direct invocations it with an SQS que, which allowed SQS to invoke the lambda functions on my behalf, and then I could check the status of all 800 invocations, with one API call to Que. This way, I could know how many functions were completed, in progress, and yet to be called.
SNS or direct invocations are faster, but they’re slower to check on — if we’re counting end-2-end timing, SQS is fastest for this use-case. Plus with SQS gradually ramping up, my Lambda invocations would not be throttled due to burst concurrency limits.
But it still wasn’t fast enough.
The change I implemented was to shard the SQS ques — why use one SQS Que, when I could use multiple. This way, I could get still get control, and error handling of SQS, but mitigate it’s speed disadvantage by simply using more ques to ramp up the invocations quicker.
So instead of just one, I made 4 SQS ques, and dumped 2000 invocations on them in parallel. All 2000 lambda functions were then invoked in 250 seconds, not bad. I imagine this isn’t the final point, we could increase the number of SQS ques and make even faster.
Don’t try this at home
Obviously the project’s goal is to go fast, but sharding SQS ques in this way may present a problem in your real-world architectures.
For one, because the ques invoke the same lambda, we might have encountered massive issues if the lambdas started to throttle — something I haven’t had time to investigate. Typically, the lambda pollers start slowing down once they hit the concurrency limit of the lambda — but perhaps if you have multiple ques for a single lambda you’d hit throttling soon.
What’s nice though, is we can configure a single DLQ for all SQS, which provides us just one place to capture all error messages.
Conclusion
Sharding is a great tool to increase speed, but SQS has an unlimited que-depth, with a generous 120,000 limit on inflight messages. The only reason to shard is to increase speed — but beware the implications of that on downstream lambda functions.