At the end of 2018, AWS introduced custom runtimes for Lambda functions, which provided customers a way to run applications written in languages not in the holy list of the ‘Official AWS Lambda Runtimes’ which include a plethora of languages. It has 3 versions of Python, 2 versions of Node, Ruby, Java, Go and .NET core (that’s a lot of language support)
Security-wise, it’s better to use an Official AWS Lambda runtime than it is to roll your own. After all, why take ownership for something AWS is already doing for you — and for free!
But, as plentiful as the official runtime list is– there’re always edge-cases where you’d want to roll your own custom runtime to support applications written in languages AWS doesn’t provide.
Maybe you absolutely have to use a Haskell component — or you need to migrate a c++ implementation to lambda. In these cases, a custom runtime allows you to leverage the power of serverless functions even when their runtimes are not officially supported.
Bash Custom Runtime
Which brings us to the topic of today’s post, the bash custom runtime.
For Klayers, I needed a way to update a github repo with a new json file every week — which can be done in python, but no python package came close to the familiarity of git pull , git add and git commit.
So rather than try to monkey around a python-wrapper of git, I decided to use git directly — from a shell script — running in a lambda — on the bash runtime.
So I pulled in the runtime a github repo I found, and used it for write a lambda function. Simple right? Well not entirely — running regular shell scripts is easy, but there are some quirks you’ll have to learn when you run them in a lambda function…
Not so fast there cowboy…
Firstly, the familiar home directory in ~/ is off-limits in a lambda function — and I mean off-limits. There is absolutely no-way (that I know off), for you can add files into this directory. Wouldn’t be a big isue, except this is where git looks for ssh keys and the known_hosts file.
Next, because lambda functions are ephemeral, you’ll need a way to inject your SSH key into the function, so that it can communicate to GitHub your behalf.
Finally, because you’ve chosen to use the bash runtime, you’re limited to the awscli utility, which while fully functional doesn’t come with the usual tools as boto3 for python. It’s a lot easier to loop and parse json in python than it is in bash — fortunately, jq makes that less painful, and jq is included in the custom runtime :).
Enough talking let’s build this
1: Loading the Environment
First we create the function — for this I used the serverless framework, and the code snippet below:
I use the provided runtime, and then attach the publicly available bash custom runtime as a layer to the function — that’s really all there is to running a lambda function in bash. To eliminate a dependency on a public layer, you could download the runtime, and deploy it in your own AWS account.
I then pre-load environment variables for the function.
- GITHUB_REPO (the ssh location of the github repo)
- KEK_PARAMETER (the parameter in SSM for the Key-Encrypting-Key)
- S3_KEYS (the bucket with the SSH keys)
- BUCKET_NAME (the bucket with the json file)
Environment variables are exactly that in lambda functions, and can be accessed directly by calling $GITHUB_REPO, $KEK_PARAMETER or whatever name you give it — just like you would in bash.
2: Loading the SSH key
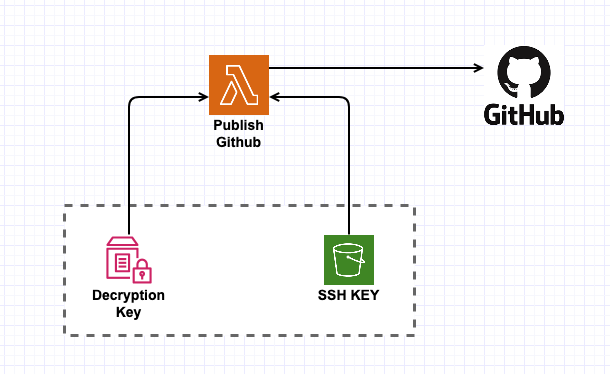
In order to push anything to GitHub we’re going to need an SSH key. That SSH key is a secret — which requires us to store it away safely somewhere.
You could just load the SSH key as a environment variable — but be cautious, the environment variable in lambda is a deploy-time dependency. Also, the environment variable is visible in the console (and anywhere else for that matter) to IAM role that has the lambda:GetFunction permission.
A recommended approach would be to store this in AWS Secrets Manager or Parameter Store. Secrets Manager is great if you’re looking for a key-rotation of RDS instances etc, for this specific use-case though, Parameter store is cheaper and gives you the same required features.
But Parameter Store has a limit, for regular parameters, the maximum size is 4KB, which is OK — but the public side of 4096-bit RSA key-pair will generally take ~3.3KB already, dangerously close to the limit. Hence I chose to store a Key-Encrypting-Key in parameter store instead — and upload an encrypted version of the key to S3. This way, I can use this pattern for any arbitrary size data. It also makes sure that I have to mess-up two IAM permissions (one for the bucket, and one for the parameter) before anyone can view the key in plaintext.
You could use other key-pairs like ECDSA, which greatly reduce the key size — but for now let’s go with 4096-bit RSA. For this, I generate a random 4096-bit RSA key, which I then encrypt with a random 48 character AES-256-CBC key. The script to do this is below:
I upload the AES key to Parameter store (manually), and the encrypted RSA key to an S3 bucket. I also need to add this SSH key as a deploy key to GitHub. GitHub only allows your deploy key to be used in one repo at a time, so you might prefer to use a user-level key instead.
The Lambda function is explicitly granted access to both the bucket, and the specific parameter in the store. With both the Key-Encrypting-Key and the Encrypted Key, the function can easily decrypt and obtain the final SSH key to use for uploading into Github.
I use the serverless-iam-roles-per-function plugin in
serverless that allows me to specify individual IAM roles for each
lambda function. This way, only this one specific function has access to
either the parameter in parameter store or the special S3 bucket
created just to store the encrypted SSH Key.
I’m only human — there’s probably a better way to do this using KMS alone, or even just Parameter store — don’t @ me!
3: Running Git Commands
Now to run the Git commands. The real secret sauce is setting the $GIT_SSH and $GIT_SSH_COMMAND variables to point to directories in the /tmp folder, everything else is pretty standard.
The code I run is the following:
The entire script is under 70 lines of code (including comments and blank-lines). Also notice how I use jq to parse the response from the awscli requests.
4: Deleting the SSH Keys
Before I exit the lambda function I delete the /tmp/.ssh directory where I store the SSH key. This is more paranoia than anything, but everything in the /tmp folder exists across lambda execution contexts. Hence you’re better off deleting this folder if it store anything of value like an SSH key.
A note about OpenSSL on Lambda
The bash custom runtime looks to be built on the Python3.6 runtime, which makes sense since awscli is written in python anyway — take that you Java lovers!
The official runtime environments came pre-packaged with a few binaries like curl, awk and openssl. However, to limit the changes in the environment, AWS rarely update these binaries from the time of the runtimes publication. Hence, the version of OpenSSL available to the python3.6 runtime (and by extension) the bash runtime — is OpenSSL 1.0.2k-fips, which is problematic because — well it’s kinda old.
More importantly to my use-case, when encrypting a file with a password using OpenSSL version 1.0.x, the key is generated by running the password through a single iteration of MD5 — which is bad. You can specify the use of sha256 instead, which is only slightly better because you cannot modify the iteration count.
You can package a better version of OpenSSL (e.g. version 1.1.xxx) in a layer, but that’s for a later date. For now, I just ensure that my password has sufficient entropy, i.e. 48 base-64 characters which is 288 bits of entropy. In the future, I’ll change this to use a better version of OpenSSL.
Conclusion
Writing a Lambda function to update a GitHub repo took a lot more effort than I initially anticipated, but the results are kinda nice.
For now, this function kicks-off once a week, and updates the Klayers repo in the process. You can see the results below: