
{kind=link}
The Serverless framework (SF) is a fantastic tool for testing and deploying lambda functions, but it’s reliance on cloudformation makes it clumsy for infrastructure like DynamoDB, S3 or SQS queues.
For example, if your serverless.yml file had 5 lambdas, you’d be able to sls deploy all day long. But add just one S3 bucket, and you’d first have to sls remove before you could deploy again. This different behavior in the framework, once you introduce ‘infra’ is clumsy. Sometimes I use deploy to add functions without wanting to remove existing resources.
Terraform though, keeps the state of your infrastructure, and can apply only the changes. It also has powerful commands like taint, that can re-deploy a single piece of infrastructure, for instance to wipe clean a DynamoDB.
In this post, I’ll show how I got Terraform and Serverless to work together in deploying an application, using both frameworks strengths to complement each other.
**From here on, I’ll refer to tool Serverless Framework as SF to avoid confusing it with the actual term serverless
Terraform and Serverless sitting on a tree
First some principles:
- Use SF for Lambda & API Gateway
- Use Terraform for everything else.
- Use a tfvars file for Terraform variable
- Use JSON for the tfvars file
- Terraform deploys first followed by SF
- Terraform will not depend on any output from SF
- SF may depend on output from terraform
- Use SSM Parameter Store to capture Terraform outputs
- Import inputs into Serverless from SSM Parameter Store
- Use
workspacesin Terraform to manage different environments. - Use
stagesin Serverless to manage different environments. stage.name ==workspace.name
In the end the deployment will look like this:
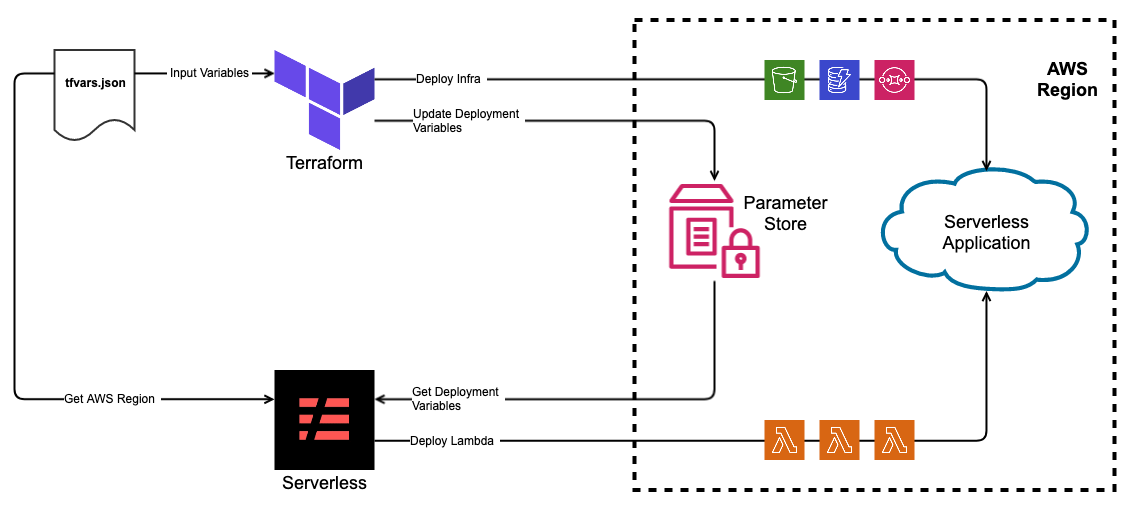
Using SSM Parameter store
AWS System Manager(SSM) parameter store is the hands-down the best way to store deployment variables. It’s a Key-Value store on AWS, that offers high scalability, data encryption at rest, and all for the very low price of free.
The real magic though is that SF can natively import ssm parameters into its deployment scripts (with no added plugins), which allow for an elegant way of getting deployment variables (like arns, bucket names and SQS urls) from Terraform into SF.
To export a variable out of Terraform onto Parameter store, use the following syntax. note: Each parameter is a resource that needs to be deployed
and then use the following to import that configuration into serverless.yml as follows:
I chose to do all my imports in the custom section of the serverless.yml file, as it gives me a single place to look for them. At this point you’re probably wondering why I chose convoluted names for the parameters — why not just temp_table instead of /${var.app_name}/${terraform.workspace}/dynamodb_temp_table
The short answer is that storing all parameters in a flat hierarchy doesn’t give us the flexibility we need to manage parameters across different environments (like dev, test, and prod) and applications. Chances are, your single AWS account is being used for multiple applications, and multiple environments in those application — hence breaking down the parameters in following form made sense:
/ <app_name> / <environment_name> / <variable_name>
But to do this properly, we need to figure out how each framework manages environments.
Stages and Workspaces
Because we pay zero for idle in serverless (at least in theory), we can effectively spin up a development environment per developer at no extra charge (theoretically!).
But to do this our tooling needs a way to separate out environments. Your single AWS account can’t have identically named DynamoDB tables or Lambda functions in a single region, worse still S3 Buckets must be uniquely named throughout AWS!
SF uses stages to separate environments. It will append the stage name to the name of the Lambda function to prevent duplicates. This naming extends to even the Cloudwatch Log Groups and IAM roles.
Terraform uses workspaces, but doesn’t automagically create different named resources for you. For this you’d either need to append the workspace name (ala SF) or use a tfvars file. Here’s an example of a tfvars file (in json format).
Here I have an app_name variable which is the same across all workspace. But then s3bucket_domains and dynamodb_temp variables are ‘maps’ that have different values for my two workspaces, default and dev. I can reference them in my Terraform script by simply looking it up, for example:
Depending on my workspace (default or dev), different variables are used and created.
Hence we see that workspace in Terraform is the same as stage in SF. If we ensure that both of them have the same values, both frameworks can align their deployments.
As long as Terraform outputs to parameter store in the form of:
/${var.app_name}/${terraform.workspace}/<variable_name>
and serverless imports variables in the form of:
/${self:service.name}/${self:provider.stage}/<variable_name>
They’ll be referencing the same value for the same environment.
For those watching closely you’d have noticed that Terraform actually has no concept of application name, hence I just created a variable named app_name that is constant throughout the application and referenced that.
But wait … what about AWS Region
For multi-regions deployment using the parameter store has a limit. How would serverless know which region’s parameter store to query?
To resolve this, we made an exception. For this one variable, i.e. the region we deploy in, we have to use a variable available locally.
For that we reference the input variable file into Terraform, i.e. the .tfvars file. A lesser known feature of this file, is that it can be written in json, which as luck would have it, SF can read natively as well.
Hence by storing the aws region in our tfvars.json file like this:
And referencing it from our serverless.yml like this:
We can make sure serverless will continue to query the right region’s parameter store for all other parameters.
Conclusion
Terraform is fantastic for laying down Infra, it doesn’t package your code, or allow you to invoke/test lambda functions.
Serverless is awesome for deploying lambda functions, it takes care of IAM roles, Cloudwatch Logs and can easily connect to event triggers throughout your AWS infrastructure, but it lacks the desired features to deploy infrastructure.
Both these tools have a purpose, and neither one is sufficient (at least to me), but together they’re pretty unstoppable. (that being said, maybe packaging in Jenkins might be a better options)
No go forth and serverless.
This is by far the best and smoothest approach I have seen. Thank you for this guide!