DNS Queries on GovScan.Info
This post is a very quick brain-dump of stuff I did over the weekend, in the hopes that I don’t forget it :). Will post more in-depth material if time permits over the weekend.
govScan.info, a site I created as a side hobby project to track TLS implementation across .gov.my websites — now tracks DNS records as well. For now, I’m only tracking MX, NS, SOA and TXT records (mostly to check for dmarc) but I may put more record types to query.
DNS Records are queried daily at 9.05pm Malaysia Time (might be a minute or two later, depending on the domain name) and will be stored indefinitely. Historical records can be queried via the API, and documentation has been updated.
Architecture of the DNS Queries
I want to spend some time walking through the architecture of DNS querying on GovScan.info, DNS queries are almost a separate distinct aspect of the site that I can draw the architecture of the DNS queries independently from other functions of the site:
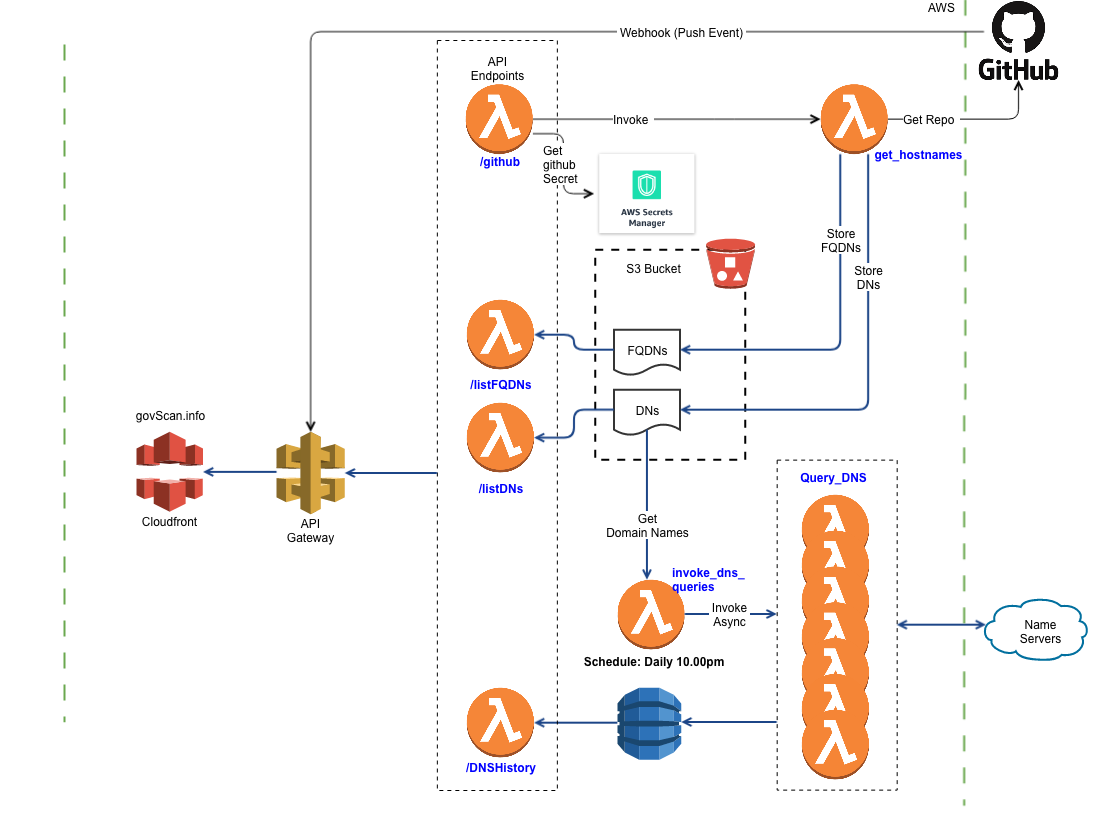
The architecture might look a bit daunting, but we can break it down into easier to understand components.
Beginning from the top of the diagram, the lambda function get_hostnames reads a GitHub repo, that contains the list of all domains to scan. The result of the read is stored in two separate .txt files in an S3 bucket. These files correspond to two API end points /listFQDNs and /listDNs respectively.
However, that get_hostnames is only invoked when there is a change to the Repo itself, and for that I use a GitHub Webhook. The Webhook will post a change to the /github endpoint, which will trigger get_hostnames. This means that the two files in the S3 bucket will remain static until there is an actual push to the Repo.
You’ll notice from the diagram that the GitHub webhook post to the API Gateway, and not via Cloudfront. This means that the webhook would post to a url that looks like this:https://xxx.execute-api.us-west-2.amazonaws.com/ProdNew/api/v2/github
rather than this:https://govscan.info/api/v2/github
The rationale for this is simply that CloudFront (at least via the GUI) did not give me the option to allow the POST method without also allowing for PUT, PATCH and DELETE, which are obvious security worries. Also, by using a the native API endpoint instead of the generic govscan.info, I’m able to hide my webhook url from the public.

Obviously we shouldn’t rely on security through obscurity alone, so I used the recommended secret implementation for GitHub webhooks. With secret enabled, GitHub will sign the entire body of the POST method with a pre-shared secret. The signed value is provided in a HTTP header, and passed along with the message, this way the end point can verify that the POST message actually does originate from GitHub.
The next challenge is of course — where to store the secret? The Lambda function that is invoked by the API should able to verify the signature, but to do that it would require the plaintext secret. I could store it in a S3 bucket, but I preferred to use AWS secret manager instead. It’s a dead-simple API to call, and will allow me more flexibility for future secrets and control via IAM roles.
I manually generated a secret with openSSL, copied it into GitHub via the GUI, and stored it in secret manager via the AWS GUI as well (although there’s no reason both of these actions can’t be automated). When GitHub POST to the endpoint, the lambda will first retrieve the secret from secrets manager, and do a compare_digest between what it calculates and what was provided, if the digest match, it performs additional validation of whether the event from GitHub is a push. Only then does it invoke theget_hostnames function.
Note: GitHub were very adamant folks use compare_digest rather than the ‘==’ syntax. Apparently, compare_digest is written in a way to prevent timing attacks on your function.
Finally, we have to grant the functions the correct permissions. Fortunately this is quite easy to do with the Serverless Framework. It’s an easy couple of lines to the yml file — note I granted the function explicit permission to read just this one secret, and nothing else, applying the principle of least privilege.
Moving on to the actual DNS queries.
The function invoke_dns_queries is scheduled (again via serverless) to run daily at 9pm Malaysian time. The function in turn will invoke asynchronously individual lambda functions to query each domain name. This means that each domain is being parallely queried, which allows me to query 613 domains in under 2 minutes.
The functions then write back their results to a DynamoDB table that exposes it’s data via the /DNSHistory endpoint.
The code is available via my GitHub repo. I’ll blog in more detail, specifically around the GitHub webhook which took me a while to build, and the lessons I learnt along the way.
The neat thing is that GitHub publishes the webhook calls from within their GUI, making it easy to troubleshoot and investigate issues. It also gives a nice green feeling for when everything works: